
SPA 개념
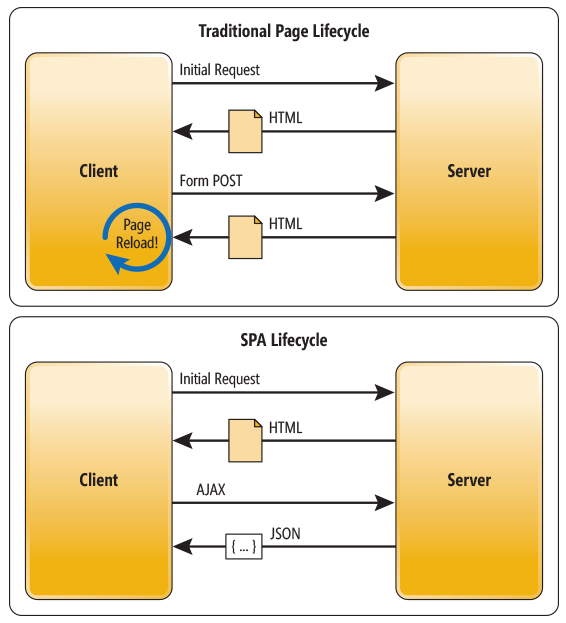
SPA는 위의 사진과 같이 처음 서버에서 한번만 HTML및 CSS파일과 JS파일을 받아온다.
그 뒤로는 이미 작성한 HTML을 body태그에 삽입하고, 소거하는 식으로 화면을 출력해준다.
아래의 코드를 보면 메인 HTML코드가 매우 단순하게 작성되어있으며, 카테고리에 소개해줄 내용HTML이 따로 존재하는 것을 알 수 있다. 이러한 내용HTML을 필요에 의해 그때그때 삽입, 소거하는 식이다.
Hashed url path vs. Non-hashed url path
Hashed url path
해시(#)이전까지의 url을 브라우저에서는 호스팅서버에서 데이터 또는 문서를 GET 받아오는 것으로 인식한다.
브라우저는 url에 #가 있으면 #포함 그 이후부터 페이지로 받아들이지 않기때문에 #뒤의 내용은 페이지로딩과 무관하다.
다만 로케이션으로 쳤던 hash값을 확인가능 (window.location으로 웹페이지정보를 확인 가능.)
ex)컴포넌트를 나눈다면 검색창 컴포넌트, 로그인창 컴포넌트, 광고창 컴포넌트식으로 나뉜다.
새로고침을 하게 되면 도메인 외 path를 서버에 요청하게 된다. Get방식으로만 했었을 때는 오류를 발생시킨다.
[네트워크 상태의 304는 브라우저에서 가지고 있는 캐싱값을 보여주는 것이다.]
SPA 로직 Process
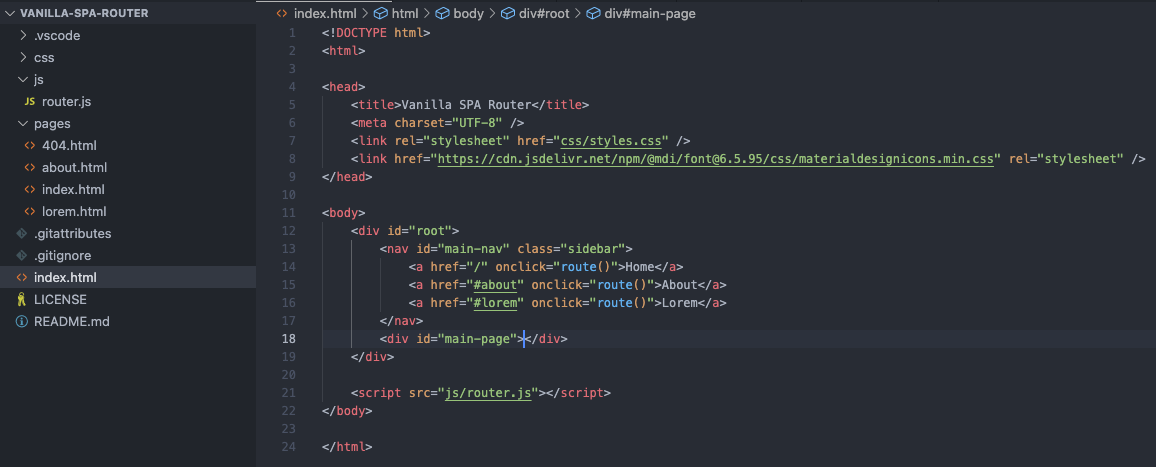
SPA를 구현할 것이므로, 호스팅서버는 오직 index.html 라는 하나의 파일만을 로드한다.
브라우저가 html, css, js 순서로 다운로드를 마치면 js/router.js 파일 내부의 로직이 시작된다.
브라우저가 index.html 파일을 완전히 다운 및 분석을 끝내면 handleLocation 함수가 실행된다.
handleLocation 함수는 현재 url path에 해당하는 page html파일위치를 파악하여 변수에 저장한 후 #main-page인 div 엘리먼트의 자식으로 저장했던 html 파일을 삽입한다.
Nav Bar나 Button 클릭을 통해서 다른 화면으로 이동할 때 마다 “hashchange 이벤트리스너”에 감지되어 다시 한번 handeLocation함수가 실행되어 #main-page의 자식 html의 내용이 변경된다.
기타 상식
자기 자신(브라우저)이 자신(본인 PC 서버)에 접근하는 경우를 Loopback 이라고 한다. 127.0.0.1 을 통상 Loopback IP address 라고 함. 사용자가 본인PC의 서버를 수동으로 수정하지 않는 한 , locahost === 127.0.0.1이다.
SPA의 장점 & 단점
| SPA장점 | SPA단점 |
| 자연스러운 사용자 경험 깜빡임 현상 X 네이티브 앱에 가까운 자연스러운 페이지 이동 (웹앱) 웹 성능 향상 필요한 리소스만 부분적으로 로딩 서버 템플릿 연산 클라이언트로 분산 생산성 향상 컴포넌트별 개발 용이 (협업 업무 분담, 유지보수) |
첫 랜딩 속도가 느림 (한번에 모든 파일 다운 → Code Splitting 고려 필요) 검색엔진최적화(SEO)에 취약함 보안 이슈 핵심 비즈니스 로직 최소화 필요 (노출 위험) SPA 장점 |
SQL (관계형 DB)
SQL을 사용하면 RDBMS에서 데이터를 저장, 수정, 삭제 및 검색 할 수 있음
관계형 데이터베이스에는 핵심적인 두 가지 특징이 있다.
- 데이터는 정해진 데이터 스키마에 따라 테이블에 저장된다.
- 데이터는 관계를 통해 여러 테이블에 분산된다.
데이터는 테이블에 레코드로 저장되는데, 각 테이블마다 명확하게 정의된 구조가 있다. 해당 구조는 필드의 이름과 데이터 유형으로 정의된다.
따라서 스키마를 준수하지 않은 레코드는 테이블에 추가할 수 없다. 즉, 스키마를 수정하지 않는 이상은 정해진 구조에 맞는 레코드만 추가가 가능한 것이 관계형 데이터베이스의 특징 중 하나다.
또한, 데이터의 중복을 피하기 위해 '관계'를 이용한다.
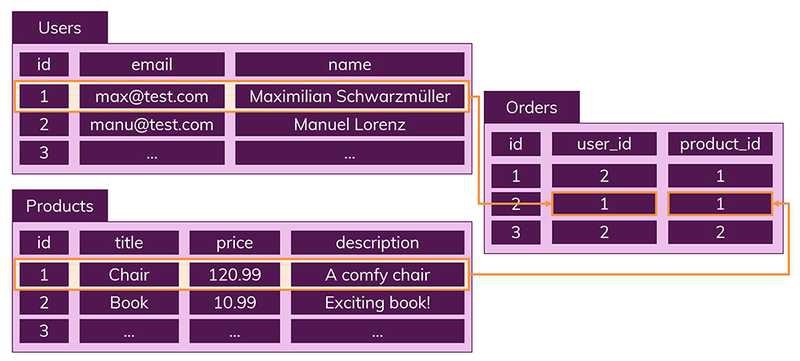
하나의 테이블에서 중복 없이 하나의 데이터만을 관리하기 때문에 다른 테이블에서 부정확한 데이터를 다룰 위험이 없어지는 장점이 있다.
NoSQL (비관계형 DB)
말그대로 관계형 DB의 반대다.
스키마도 없고, 관계도 없다!
NoSQL에서는 레코드를 문서(documents)라고 부른다.
여기서 SQL과 핵심적인 차이가 있는데, SQL은 정해진 스키마를 따르지 않으면 데이터 추가가 불가능했다. 하지만 NoSQL에서는 다른 구조의 데이터를 같은 컬렉션에 추가가 가능하다.
문서(documents)는 Json과 비슷한 형태로 가지고 있다. 관계형 데이터베이스처럼 여러 테이블에 나누어담지 않고, 관련 데이터를 동일한 '컬렉션'에 넣는다.
따라서 위 사진에 SQL에서 진행한 Orders, Users, Products 테이블로 나눈 것을 NoSQL에서는 Orders에 한꺼번에 포함해서 저장하게 된다.
따라서 여러 테이블에 조인할 필요없이 이미 필요한 모든 것을 갖춘 문서를 작성하는 것이 NoSQL이다. (NoSQL에는 조인이라는 개념이 존재하지 않음)
#SQL 장점
- 명확하게 정의된 스키마, 데이터 무결성 보장
- 관계는 각 데이터를 중복없이 한번만 저장
#SQL 단점
- 덜 유연함. 데이터 스키마를 사전에 계획하고 알려야 함. (나중에 수정하기 힘듬)
- 관계를 맺고 있어서 조인문이 많은 복잡한 쿼리가 만들어질 수 있음
- 대체로 수직적 확장만 가능함
#NoSQL 장점
- 스키마가 없어서 유연함. 언제든지 저장된 데이터를 조정하고 새로운 필드 추가 가능
- 데이터는 애플리케이션이 필요로 하는 형식으로 저장됨. 데이터 읽어오는 속도 빨라짐
- 수직 및 수평 확장이 가능해서 애플리케이션이 발생시키는 모든 읽기/쓰기 요청 처리 가능
#NoSQL 단점
- 유연성으로 인해 데이터 구조 결정을 미루게 될 수 있음
- 데이터 중복을 계속 업데이트 해야 함
- 데이터가 여러 컬렉션에 중복되어 있기 때문에 수정 시 모든 컬렉션에서 수행해야 함 (SQL에서는 중복 데이터가 없으므로 한번만 수행이 가능)
'내일배움캠프[4기_Reac트랙] > TIL' 카테고리의 다른 글
| 내일배움캠프 React트랙 15일차 회고 (2022.11.18) (0) | 2022.11.21 |
|---|---|
| 내일배움캠프 React트랙 14일차 회고 (2022.11.17) (1) | 2022.11.17 |
| 내일배움캠프 React트랙 12일차 회고 (2022.11.15) (1) | 2022.11.15 |
| 내일배움캠프 React트랙 11일차 회고 (2022.11.14) (1) | 2022.11.14 |
| 내일배움캠프 React트랙 2주차 회고 (2022.11.13) (1) | 2022.11.13 |